

Health & Wellness
Cisco IT’s observability technique

Feb
Within the face of rising IT complexity, Cisco IT unified observability throughout its world atmosphere. The outcomes: 25% fewer main incidents, 45% quicker decision, and scalable automation. Right here’s how we did it—and proposals to your digital resilience journey.
Our problem: fragmented visibility
Many organizations wrestle with fragmented monitoring and extended incident decision. We confronted the identical challenges and wanted to interrupt down information silos to guard our fast-changing atmosphere.
In Cisco IT, managing our world, dispersed IT panorama is more and more complicated. Fragmented information and visibility gaps have been making it more and more troublesome to take care of digital resilience amid our fast-paced innovation and frequent environmental adjustments. We would have liked a option to flip our information into actionable insights however lacked a unified observability platform to centralize and make sense of all of it.
When a significant database outage in 2024 revealed our fragmented information — uncorrelated alerts throughout associated gadgets delaying trigger identification — we knew we needed to rethink our observability method.
“After the outage, we knew we needed to rethink all the things. The transformation wasn’t nearly know-how, however empowering our engineers to behave quicker and smarter.”
– Chuck Churchill, Snr. Director, IT Observability, Cisco IT
This inflection level sparked a broader shift in how Cisco IT approached observability. Within the video under, Cisco IT leaders share what modified — and the way it led to a 25% discount in main incidents.
Getting began
Like several IT concern, understanding the basis trigger was important earlier than remediation planning may start. Constructing stronger digital resilience isn’t any totally different.
In working with our groups, we pinpointed the next as prime problem areas that have been hindering our efforts:
- Fragmented information and visibility gaps: With over 100,000 endpoints, we generated huge volumes of telemetry information. Siloed monitoring instruments led to alert fatigue and visibility gaps, slowing response occasions and limiting our potential to foretell and stop points.
- Dangers from frequent adjustments: Our tradition of innovation and early adoption means fixed adjustments to our IT environments. We noticed a direct hyperlink between fast change and elevated incidents, so minimizing disruption with out slowing innovation grew to become important.
- Useful resource optimization: As our surroundings and information complexity grew, it grew to become crucial to enhance how we leverage AI and information extra successfully. We would have liked to show our information into actionable insights that empower engineers, not overwhelm them, to make sure productiveness stored tempo with development.
“Bringing all our information collectively was step one—turning it into actual, actionable insights is what really allows us to remain resilient as our surroundings evolves.”
– Jon Heaton, Director, Community Engineering and Operations, Cisco IT
Deciding on our three-pronged observability method
Digital resilience requires greater than merely deploying new instruments. We would have liked a holistic method that may span our total IT panorama. We obtaind this by structuring our IT observability observe throughout three interconnected pillars:

- The community: Safe, dependable community efficiency is crucial for conserving the enterprise up and operating. This pillar focuses on complete community visibility, together with third–occasion supplier networks, to make sure the community is operating securely and optimally for a clean person expertise.
- Platforms and information: Right here, we concentrate on observability throughout our information facilities, cloud, and underlying infrastructure, centralizing our observability information to be accessible to the whole group, together with our DevOps and SRE groups, via our platform consolidation and information technique.
- Service Operations: Our Service Operations and Enterprise Operations Heart engineers monitor, analyze, and resolve points utilizing wealthy information and insights delivered from our community, infrastructure, functions and companies — which feed AI automation to enhance effectivity.
Including within the crucial know-how
Every of those observability pillars is powered by a mix of information, know-how, and processes that allow us to make use of the total potential of our information and drive better effectivity via AI automation. These core components are important to our observability method and success:
- Splunk: Splunk acts because the spine of our observability technique, centralizing information from throughout our community, infrastructure, and functions to ship a single supply of fact for our IT groups.
- ThousandEyes: ThousandEyes delivers end-to-end community visibility and person expertise monitoring throughout inside and exterior environments, enabling fast identification and determination of connectivity points.
- Configuration Administration Database (CMDB): Our CMDB offers a single supply of fact for all IT property, enriching alerts and incidents with important context and powering environment friendly, proactive operations.
- AI Operations: Our AI techniques leverage the centralized observability information in Splunk to automate occasion evaluation, cut back alert fatigue, and speed up incident response — empowering engineers to concentrate on higher-value work. For instance, our Service Operations makes use of varied AI assistants for AI-driven incident administration to foretell incident assignments and counsel decision steps.
By integrating Splunk with ThousandEyes, our CMDB, and different instruments, we will guarantee a seamless, scalable method to observability that grows with our enterprise.
Tangible outcomes
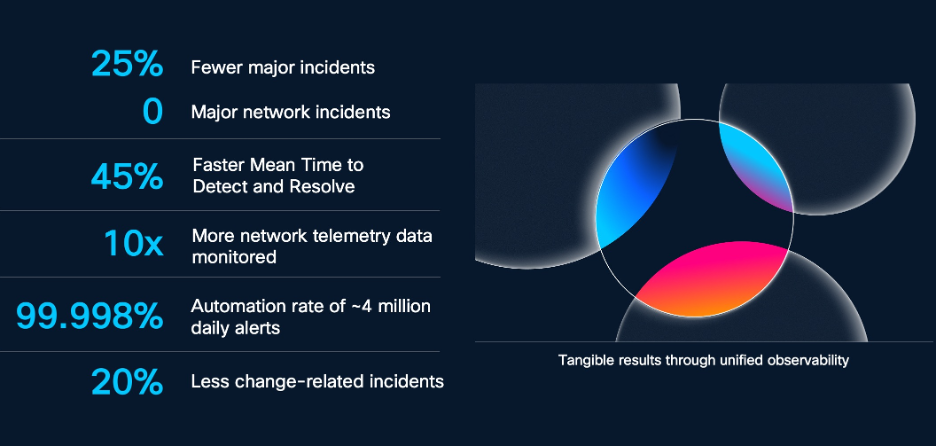
This unified observability method has helped us sort out our most urgent challenges and enhance outcomes that collectively strengthen our digital resilience. Prior to now 18 months, we’ve seen:
- Vital discount in main incidents: We lowered main incidents by 25% 12 months over 12 months and had zero main community incidents, down from 3-4 per quarter beforehand.
- Sooner, simpler restoration: We lowered our Imply Time to Detect and Resolve by 45% 12 months over 12 months, enabling quicker restoration and minimized disruption.
- Improved change administration: We decreased incidents attributable to change by 20%, enabled by unified information insights and end-to-end visibility that helps smarter change administration processes.
- Strengthened visibility and information utilization: We now monitor 10x extra community telemetry information that yields deeper insights and 4x better visibility — enabling earlier detection and proactive decision of potential points earlier than they escalate.
- Scalable automation and effectivity: Centralizing information in Splunk has established a basis for continued developments in AIOps, enabling us to develop AI-automations that now deal with 99.998% of ~4 million each day alert — considerably enhancing operational effectivity.
“This journey is as a lot about altering mindsets as deploying know-how. We’re empowering each engineer to behave on insights, not simply alerts.”
– Mark Hutchins, Director, IT Service Administration, Cisco IT
Sensible takeaways
Our digital resilience journey is ongoing, however we be taught extra every day that we share with clients enhancing their very own journey. We suggest:
- Accumulate telemetry from in every single place: Centralize telemetry to optimize essentially the most related metrics, occasions, logs and traces from throughout your community, infrastructure, cloud, functions, and companies.
- Prioritize information – the bedrock of success: concentrate on information high quality and hygiene. Correct, clear information is crucial for producing reliable insights and enabling efficient automation.
- Use what’s already sensible: First, leverage the techniques that you’ve: product capabilities which have AI and observability in-built. Second, empower groups to experiment with customized AI options to maximise worth the place your present techniques have gaps.
Keep tuned for updates and learnings as we proceed to innovate and optimize.
“Digital resilience is a shifting goal. We’re at all times studying, adapting, and refining our method as our surroundings evolves.”
– Jon Heaton, Director, Community Engineering and Operations, Cisco IT
Extra sources:
Discover extra case research to see how Cisco strengthens digital resilience




